들어가며
우리는 개발자로서 자신이 만든 웹페이지가 많은 사용자들에게 노출되기를 바랄 것이다. 필자 또한 이 블로그를 노출 시키기 위해 SEO에 대해 학습하고 적용하는 경험을 했다. 이번 포스팅에서는 이러한 경험들에 대해 작성해보려고 한다.
SEO
SEO는 Search Engine Optimization 의 약자로 웹페이지가 검색 결과에서 높은 순위를 차지하도록 최적화하는 기술과 전략을 의미한다. 이를 통해 더 많은 트래픽을 유도하고, 사용자에게 유용한 정보를 제공하며, 궁극적으로 웹페이지의 가치를 높이는 것을 목표로 한다.
한마디로 가치 있는 웹페이지를 구현할수록 검색엔진은 웹페이지에게 높은 순위를 부여하며, 순위가 높을 수록 검색 결과 상단에 위치하게 된다.
SEO는 마케팅이다
필자 뿐만 아니라 많은 개발자들이 본인의 서비스를 개발하기 위해 다양한 기술 스택을 공부하고, 더 나아가 예쁜 코드를 작성하려고 노력한다.
그러나 이렇게 공들여 개발한 서비스가 항상 시장에서 좋은 평가를 받을 수 있을까?
시장에서 우리의 서비스를 사용하는 소비자는 요즘 핫한 기술이 적용되었는지, 코드가 예쁘게 작성되었는지에는 대부분 관심이 없다. 유저 입장에서는 서비스가 문제 없이 동작만 하면 되는 것이다.
(그렇다고 유지보수가 힘든 코드를 작성해도 된다는 것은 아니다)
그렇다면 서비스가 성공하기 위해서는 어떻게 해야할까? 정말 다양한 요소가 작용하겠지만, 필자는 서비스가 시장에서 성공하기 위해서 코드의 품질이나 사용된 기술의 최신성보다는 사용자들이 쉽게 접근할 수 있는지에 달려 있다고 생각한다. 많은 사용자가 서비스를 이용하게 되려면, 특정 키워드로 검색했을 때 상위에 노출되어야 하고, 이를 통해 자연스럽게 유입이 이루어져야 한다. 결국 사용자들에게 자주 노출되는 것이 중요한 것이다.
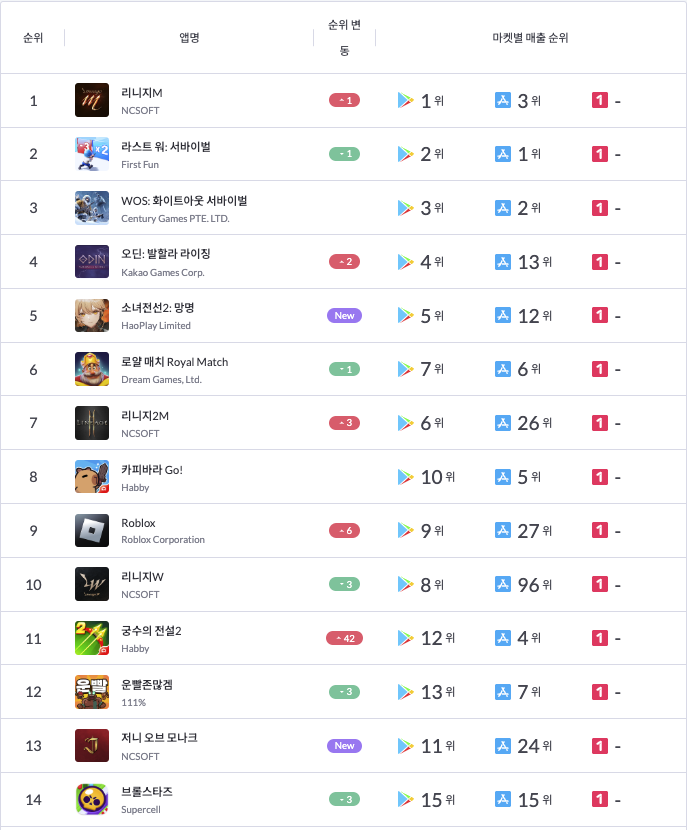 출처 : 모바일인덱스
출처 : 모바일인덱스
위 사진을 보면 규모가 큰 개발사에서 개발한 게임과, 유튜브 광고에서 매번 등장하는 저퀄리티 게임등이 존재한다. 하지만 많은 인력과 자금을 투입한 게임보다도 유튜브 광고에 등장하는 저예산 게임들의 수익이 높은 경우도 존재한다.
결국 서비스는 많은 사람들에게 노출되어야 하며, 웹페이지를 노출시키기 위해 우리는 SEO를 해야한다.
SERP
SERP는 Search Engine Result Page 의 약자로, 검색엔진 결과 페이지를 의미한다. 사용자가 검색엔진에 질의를 입력했을 때, 그에 대한 결과가 표시되는 페이지를 말한다. SERP는 사용자의 검색 의도에 맞춰 다양한 형태의 결과를 제공하는데, 여기에는 웹페이지 링크, 이미지, 동영상, 뉴스 기사, 지도 정보 등이 포함될 수 있다.
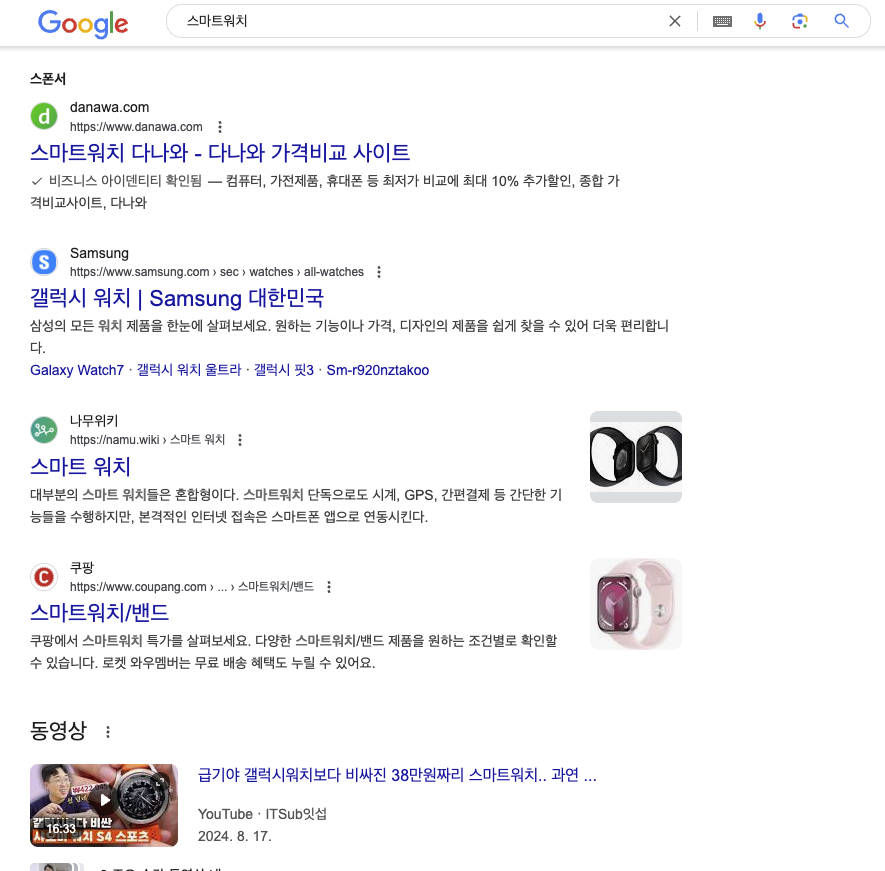
필자는 구글 검색창에 스마트워치 키워드를 검색했다. 지금 보고 있는 검색 결과 화면이 SERP 이며 SERP 는 크게 두 영역으로 볼 수 있다. 상단 스폰서 키워드가 있는 페이지 링크들은 광고 영역, 스폰서 키워드가 붙지 않은 하단 영역을 자연 검색 영역이라고 한다.
보통 사용자의 경우 광고 영역보다 자연 검색 영역을 더 신뢰한다. 필자 또한 광고 영역을 클릭한 기억이 거의 없을 정도이다. 그렇기에 우리는 SERP 에서 자연 검색 영역 상단에 웹페이지가 위치할 수 있도록 SEO 작업을 수행해야 한다.
구글 검색 엔진 동작
그렇다면 검색 엔진은 어떻게 동작할까?
구글 검색 엔진을 예시로 들어 검색 엔진이 어떻게 동작하는지 알아보자. 구글 검색 엔진은 크게 3가지 단계로 나뉘어 동작한다. 구글봇이 웹페이지 컨텐츠를 수집하는 크롤링 (Crawling), 수집한 정보를 주제별로 색인해서 보관하는 인덱싱 (Indexing) 마지막으로 검색 의도에 맞춰 콘텐츠에 순위를 부여하는 랭킹 (Ranking) 으로 나뉘어 동작한다. 구글 검색 엔진의 자세한 구조도를 보고 싶다면 아래 그림과 주소(구글 검색 엔진 논문)를 참고하자.
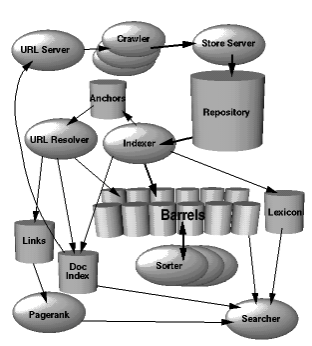 높은 수준의 Google 아키텍처
높은 수준의 Google 아키텍처
크롤링
구글 봇은 웹페이지의 콘텐츠를 수집한다. 이 글을 작성하고 있는 시점에도 새로운 웹페이지는 계속해서 등장하고 있다. 하지만 이 모든 웹페이지가 등록되는 중앙 레지스트리는 없기 때문에 계속해서 새 페이지와 업데이트된 페이지를 파악해야 한다.
구글 아키텍처 그림을 확인해보자. URL 서버에서 크롤러에게 URL 목록을 전송한다. 전달받은 URL은 여러 분산 크롤러에 의해 크롤링되며, 크롤링 된 데이터를 스토어 서버에 전송한다. 이후 압축하여 레포지토리에 저장한다.
크롤러가 모든 페이지를 크롤링하는 것은 아니다. 사이트 소유자는 크롤링을 허용하지 않는 페이지를 정의할 수 있다. 크롤링을 허용하지 않는 페이지를 정의해 둔다면 크롤러는 해당 페이지를 크롤링하지 않는다.
크롤링을 허용하지 않는 방법에 대해서는 robots.txt 작성법에서 살펴보자.
색인 생성
인덱싱 기능은 인덱서 및 소터 에 의해 수행된다. 인덱서는 여러 기능을 수행하며 대표적으로 문서의 압축을 풀고, 구문을 분석한다. 그리고 각 문서는 히트 라는 단어 발생 집합으로 변환된다. 히트에는 단어, 문서 내 위치, 글꼴 크기, 대문자 등이 기록된다. (필자는 히트가 잘 이해가지 않아서 하나의 객체로 생각하고 학습했다). 인덱서는 히트를 배럴 로 분배하여 부분적으로 정렬된 인덱스를 생성한다.
인덱서는 또 다른 기능을 수행하는데, 모든 웹 페이지의 링크를 구문 분석을 수행하고 링크에 대한 정보를 앵커 에 저장한다. 이 앵커 파일에는 링크의 출발지, 목적지, 링크의 텍스트등의 정보가 포함되어 있다.
검색결과 게재
구글은 각 히트를 여러 가지 유형 중 하나로 간주하며, 각 유형별로 가중치가 설정되어 있다. 유형 가중치는 유형별로 인덱싱된 벡터를 구성하며, 히트 목록에서 각 유형의 히트 횟수를 계산한다.
그런 다음 모든 카운트는 카운트 가중치로 변환한다. 카운트 가중치는 처음에는 카운트에 따라 선형적으로 증가하지만 빠르게 감소하여 특정 카운트 이상은 도움이 되지 않는다. 카운트 가중치 벡터와 유형 가중치 벡터의 도트 곱을 구하여 문서의 IR 점수를 계산한다. 마지막으로 IR 점수와 PageRank를 결합하여 문서에 최종 순위를 부여한다.
SEO 작업을 해보자
구글 검색 엔진 논문을 읽어보며 구조에 대해 학습했다. 다음으로는 이 블로그를 만들며 Nextjs에서 SEO를 위해 작업했던 내용들을 정리하려고 한다.
메타태그
메타태그는 웹페이지 정보를 명시하기 위한 목적으로 사용되는 HTML 태그이다. 필자는 아래와 같이 작성했다. 여러 페이지에서 자주 사용하게 되는 값들은 분리해서 사용중이다. 이 방식은 shadcnui 레포지토리를 참고했다.
// /src/config/site/index.ts
export const siteConfig = {
name: '김현재 | Napol',
url: 'https://www.napol.dev',
ogImage: 'https://www.napol.dev/opengraph-image.png',
description: '현재가 작성하는 현재의 개발 기록',
links: {
github: 'https://github.com/NapolDeveloper',
},
};
export type SiteConfig = typeof siteConfig;// /app/layout.tsx
export const metadata: Metadata = {
title: {
default: siteConfig.name,
template: `%s`,
},
metadataBase: new URL(siteConfig.url),
description: siteConfig.description,
keywords: [
'프론트엔드',
'자바스크립트',
'타입스크립트',
'리액트',
'넥트스',
'frontend',
'js',
'javascript',
'ts',
'typescript',
'react',
'nextjs',
],
authors: [
{
name: 'Napol',
url: 'https://www.napol.dev',
},
],
creator: 'Napol',
openGraph: {
type: 'website',
locale: 'ko_KR',
url: siteConfig.url,
title: siteConfig.name,
description: siteConfig.description,
siteName: siteConfig.name,
images: [
{
url: siteConfig.ogImage,
width: 1200,
height: 630,
alt: siteConfig.name,
},
],
},
twitter: {
card: 'summary_large_image',
title: siteConfig.name,
description: siteConfig.description,
images: [siteConfig.ogImage],
creator: '@napol',
},
icons: {
icon: '/favicon.ico',
},
manifest: `${siteConfig.url}/site.webmanifest`,
verification: {
other: {
'naver-site-verification': '9c40f297bb089b11c9605077e36f31c1c8203b19',
},
},
};사이트맵 (sitemap)
사이트맵은 사이트에 있는 페이지, 동영상 및 기타 파일과 그 관계에 관한 정보를 제공하는 파일이다.
필자는 아래와 같이 구성했다.
// /app/sitemap.ts
import type { MetadataRoute } from 'next';
import { siteConfig } from '@/config/site';
import { getCategoryList, getPostList } from '@/lib/post';
export default async function sitemap(): Promise<MetadataRoute.Sitemap> {
const categoryList = getCategoryList();
const postList = await getPostList();
const generatedCategorySitemap = categoryList.map(category => ({
url: `${siteConfig.url}/blog/${category}`,
lastModified: new Date(),
}));
const generatedPostSitemap = postList.map(post => ({
url: `${siteConfig.url}${post.url}`,
lastModified: post.date,
}));
return [...generatedCategorySitemap, ...generatedPostSitemap];
}필자의 블로그는 포스트가 추가될 때마다 포스트의 주소 또한 추가되기에 동적으로 사이트맵 파일을 생성하는 코드를 작성했다.
robots.txt
위 크롤링 파트에서 잠깐 언급했던 부분이다. 크롤러에게 특정 페이지에 대해 크롤링 허용/제한을 하는 파일이다.
// /app/robots.ts
import type { MetadataRoute } from 'next';
import { siteConfig } from '@/config/site';
export default function robots(): MetadataRoute.Robots {
return {
rules: {
// 크롤러 지정
userAgent: '*',
// 크롤링을 허용할 경로
allow: '/',
},
sitemap: `${siteConfig.url}/sitemap.xml`,
};
}마무리
사실 필자가 적은 내용을 제외하고도 SEO에는 엄청나게 많은 내용들이 남아있다. 하지만 포스팅 하나에 전부 담기에는 벅차다. 따라서 더 공부하고 싶은 독자분들을 위해 밑에 참고 자료들 링크를 첨부하니 SEO에 대해 궁금하다면 꼭 확인해보도록 하자.
기회가 된다면 첨부해둔 내용에 대해서도 포스팅을 진행해보도록 하겠다.
"오늘의 한줄 : 서비스 기능 개발만큼 중요한 것이 SEO 작업이다. 우리의 서비스를 유저들에게 잘 마케팅하자"
아래 링크에서는 본 포스팅에서 다루지 않은 SEO의 범위에 대해 자세히 설명해주며, 각 SEO 영역에서 어떤 작업들이 가능한지 설명해준다.
tbwakorea SEO